基本介绍
这是能用AI技术生成图片的开源软件,只要给定一组描述文本,AI就会开始绘图(准确的说是「算图」或「生图」);亦能模仿现有的图片,生成另一张图片。甚至给它一部分涂黑的图片,AI也能按照你的意愿将图片填上适当的内容。除此之外还支持自行训练模型加强生图效果。
环境搭建
我最先使用的是下面介绍①的版本,但是缺少很多插件,用着不是很方便,于是使用了介绍②的版本。
版本①
关键步骤
此处以windows为例,其他操作系统可查看底部链接。
python、Anaconda等环境的搭建也可参考文章底部链接。
- 在终端输入以下代码
1 | git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
- 设置启动命令行参数
对stable-diffusion-webui文件夹里面的webui-user.bat按右键,以记事本打开。
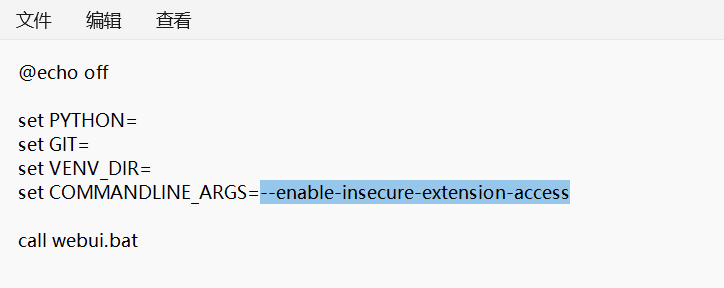
接着您要编辑set COMMANDLINE_ARGS=这一行启动参数。
若显卡VRAM在8GB以上,将set COMMANDLINE_ARGS=替换成set COMMANDLINE_ARGS=--enable-insecure-extension-access参数。
显卡VRAM小于等于4GB,将set COMMANDLINE_ARGS=替换成set COMMANDLINE_ARGS=--medvram --opt-split-attention --enable-insecure-extension-access参数。加上--medvram的用意是为了限制VRAM占用。
电脑RAM(不是VRAM)小于等于8GB的话改替换为set COMMANDLINE_ARGS=--lowvram --opt-split-attention --enable-insecure-extension-access参数。注意使用--lowvram参数会让高端显卡算图变很慢。
(下面的不加也可以)
加上--xformers可进一步减少VRAM占用,只支持Nvidia显卡。加入--no-half-vae减少使用VAE算出黑图的几率。
加上--listen参数再开放防火墙7860通信端口,即可用局域网路其他电脑的浏览器访问WebUI。
加上--share参数则会产生一组Gradio网址,让你可以从外部网络或手机使用WebUI。网址72小时后过期。
其余可用参数请见命令行参数
之后就可以双击
webui-user.bat文件运行了报错解决
出现报错缺少相关配置,且系统因某些原因无法自己安装该配置
1
AssertionError: Couldn't find Stable Diffusion in any of: ['E:\\stable-diffusion-webui-arc-directml\\repositories/stable-diffusion-stability-ai', '.', 'E:\\']
通过以下代码,在根目录新建
openai文件夹,并在该文件夹中克隆相关配置1
git remove https://www.modelscope.cn/AI-ModelScope/clip-vit-large-patch14.git
torch版本无法适配
根据
requirements_versions.txt文件要求以及终端提示,通过安装对应版本torch实现目标1
pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url https://download.pytorch.org/whl/cu121
版本②
关键步骤
这次使用了up主秋葉aaaki的sd版本,选择合适的版本下载后即可点击A绘世启动器.exe启动。
具体流程该up主有专门的视频)进行介绍
使用教程
参数
Prompt
提示词,通过,符号分隔
Nagative Prompt
告诉ai要避免哪些内容。
此处一般是选择embeding的一些内容,用于避免一些基本错误(如多个手指等,虽然加上这些出来的图也有可能出现多个手指)。对于版本②,如果没有修改embedding文件夹中的内容的话,默认放置的四个基本错误都可以添加在Nagative Prompt中。
模型
模型一般通过大模型(checkpoint),以及Lora,embedding,VAE,hypernetworks,ControlNet等共同生成。之前在学习过程中又看到一个很有意思的说法:大模型->游戏本体,embedding->小mod,Lora->dlc。下面也将详细介绍一些常见的模型。
模型的获取
模型我一般都是在civitai)中获取。
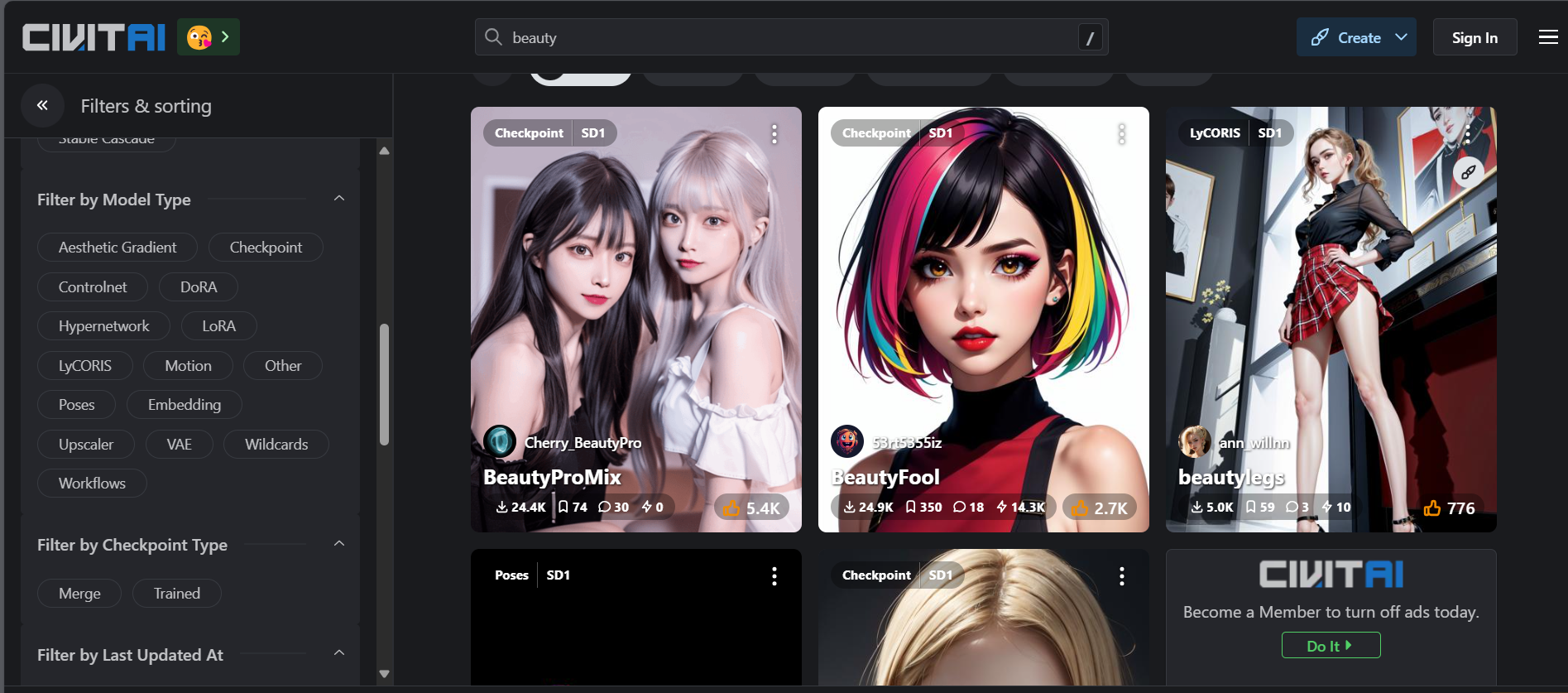
如图所示,图片的左上角有两个参数,第一个表示的是什么类型的模型,第二个表示是基于什么技术的模型。如果使用的是stable-diffusion,那么如果第二个参数为小马的图标(pony),那么将无法正常使用模型。
选择你心仪的模型,点击download可以获取safetensors或pt文件,将每个模型放在对应的文件夹下
checkpoint
模型的存储地址为/models/stable-diffusion/
checkpoint是整个ai图像制作的大模型,是决定图片类型的基调(是现实风格还是漫画风格)。
embedding
模型的存储地址为/embeddings
可以把embeddings理解为一些提示词的词包/集合,这样可以避免输入过多的提示词。(可以看到embedding也就几十KB)
VAE
模型的存储地址为/models/VAE
可以理解为添加某种滤镜
Lora
模型的存储地址为/models/Lora
Lora是某个具体的描述,比如你要生成具体某个人的相关图片,涉及到这个人的五官、装饰等细节,那就可以使用Lora模型来在提示词中告诉ai,我需要一个***的人。
hypernetworks
模型的存储地址为/models/hypernetworks
也是用于改变画风,但相比于大模型的画风,超网格实现的是比如梵高/莫奈的画风。
参考文献
https://docs.stablediffusion.cn/article/1/592976494007943168.html
【AI绘画·24年8月最新】Stable Diffusion整合包v4.9发布!解压即用 防爆显存 三分钟入门AI绘画 ☆更新 ☆训练 ☆汉化 秋叶整合包_哔哩哔哩_bilibili