lambda表达式的理解
lambda表达式的具体定义可以去网上找,我对它的理解就是将一个函数以更简洁的方式,以表达式的形式内嵌在某个函数中。
lambda表达式的应用场景
lambda表达式最常用的是在sort函数中,把cmp函数以lambda表达式直接写在内部,代码如下:
1 | sort(a.begin(),a.end(),[&](int x,int y){//此排序采用降序排序 |
等价于
1 | bool cmp(int x,int y){ |
给定一串字符串,求其中有多少长度>=3子串,且该子串中某个字符只出现一次。
最终答案的求取可以通过遍历以i位置为所要求的只出现一次的字符所对应的子串数量来求取。
然后显然我们不可能直接对于每个字符c,都暴力的去找左边有多少个相邻的连续的连续的字符与c不同,以及右边有多少个相邻的连续的连续的字符与c不同。于是,我们需要通过预处理,来记录每个字符左右两边分别有多少个相邻的、连续的、与此字符不同的字符,最终的答案也可以理解为左边挑
由于还有一个限制是长度>=3,所以对某一边没有符合要求的字符时,需要另一边减去只取一个字符的情况,即:
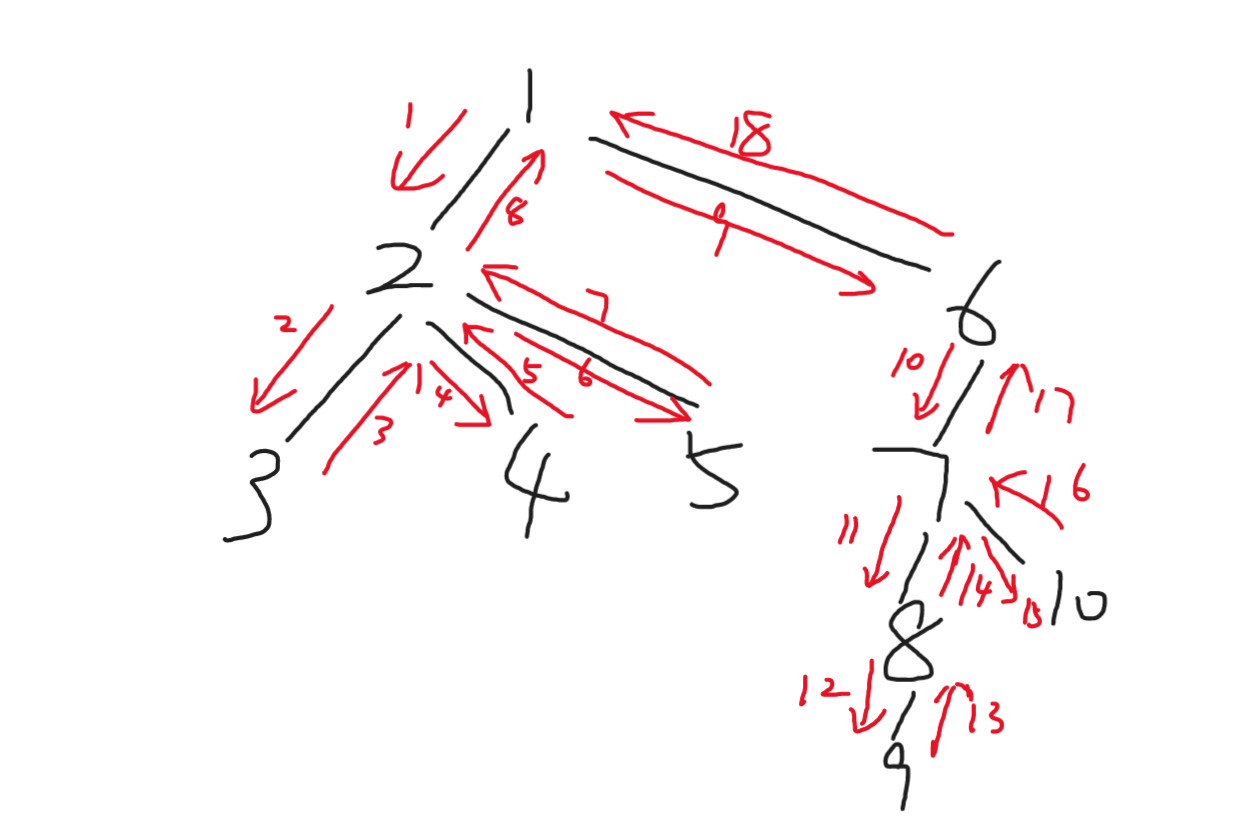
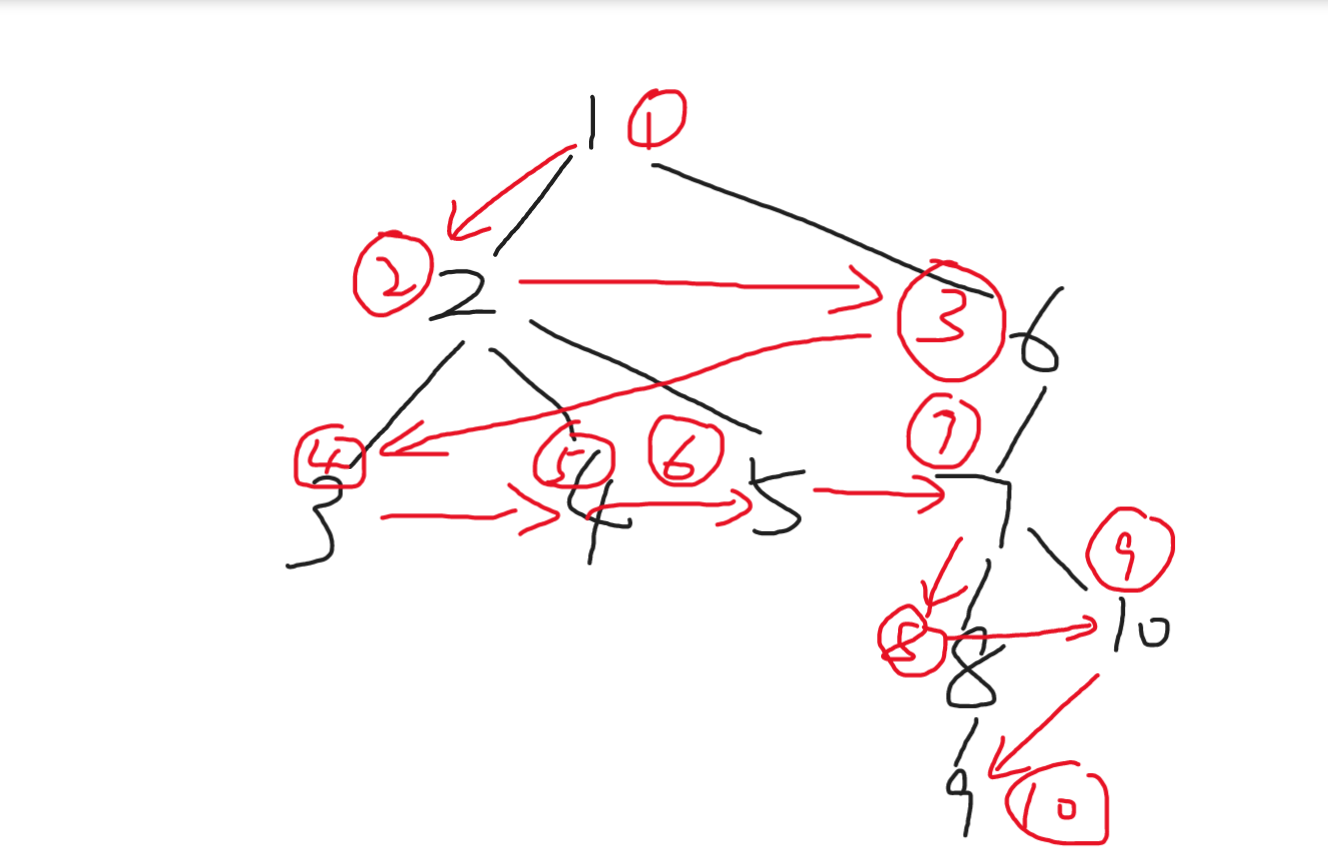
DFS,即深度优先搜索,经常用于暴力以及图上遍历等。相比于bfs,dfs是纵向的搜索,是一次性找到底的。从根找到底,然后退回来换条路继续走到底,直到走完。
DFS可以理解为是递归+回溯。对于一棵DFS树,其搜索的方式是从根结点开始,沿着一条边一直走到底,层层递归,每次进入一个子节点就可以理解为一个新的以此子节点为根的DFS树,称之为递归。当访问到叶子结点时,又需要将叶子结点的信息返回并总结到该叶子节点的父亲节点,称之为回溯。
DFS大部分分为树上DFS与图上DFS,但其实两者是相通的,图上DFS可以将上下左右四个方向的遍历结果转化为该位置的四个儿子结点,此时还需要一个vis数组用来记录该儿子结点是否在别的分支出现过,尽管从一个点到另一个点会有多条路径,但如果不是要求最短路径的情况下,往往只需要记录一次即可。